Overview
📄 Read the Full Paper | 💻 Code | 🖼️ Poster | 🎤 Slides
Pretrained language models (PLMs) are central to natural language processing, but adapting them to new languages remains challenging. While previous methods introduce new embedding layers for different languages, they can be data- and compute-intensive.
We propose an active forgetting mechanism during pretraining, enabling PLMs to adapt more efficiently. By resetting the embedding layer every K updates during pretraining, we encourage the PLM to quickly learn new embeddings, similar to meta-learning. Experiments with RoBERTa show that models trained with this mechanism adapt faster to new languages and outperform standard models in low-data settings, particularly for languages distant from English.
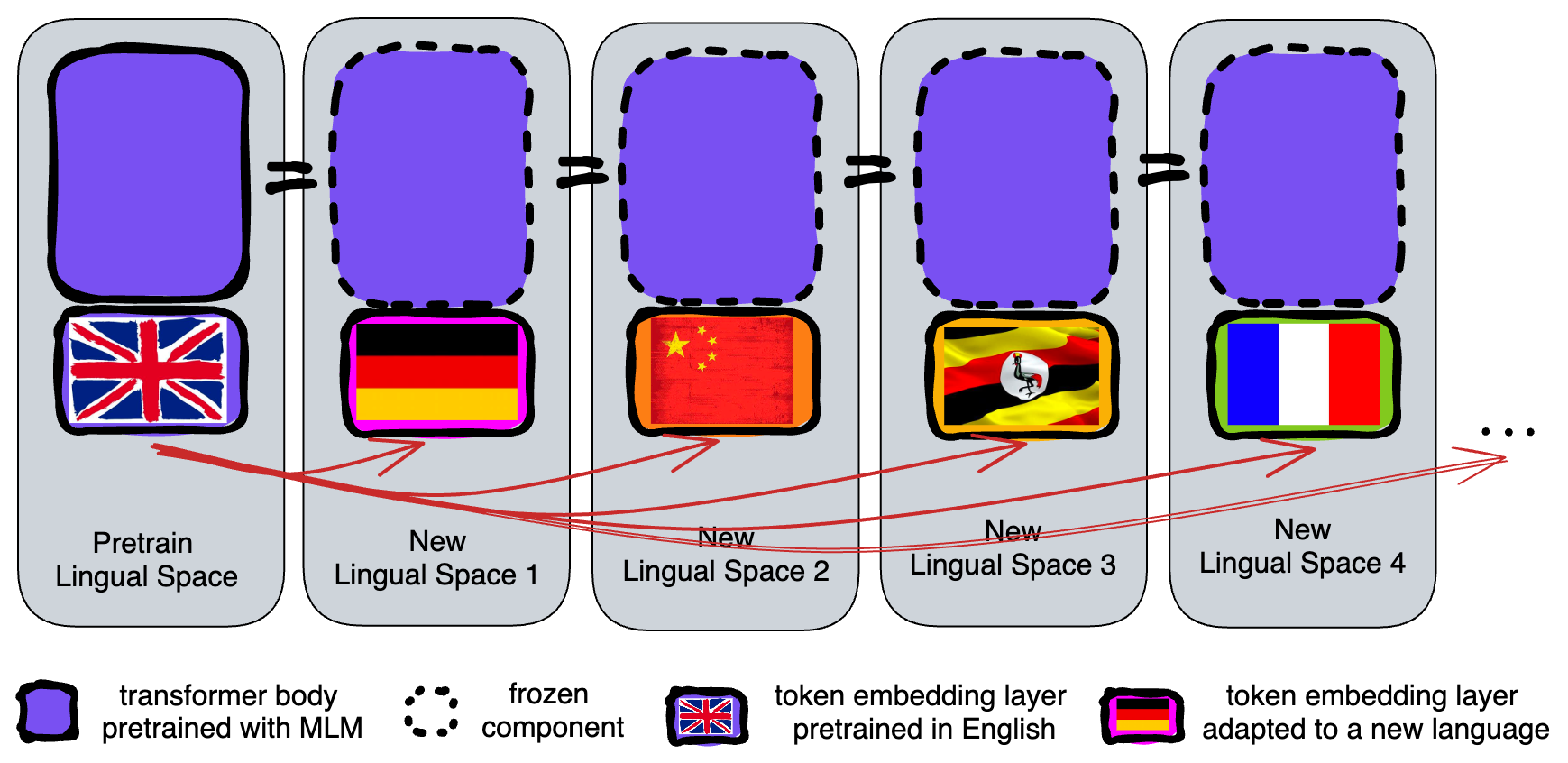
Pretraining with Active Forgetting
We introduce an active forgetting mechanism that resets the token embedding layer periodically. This involves reinitializing the embedding layer and related training elements (e.g., optimizers, learning rate schedulers) every K gradient updates.
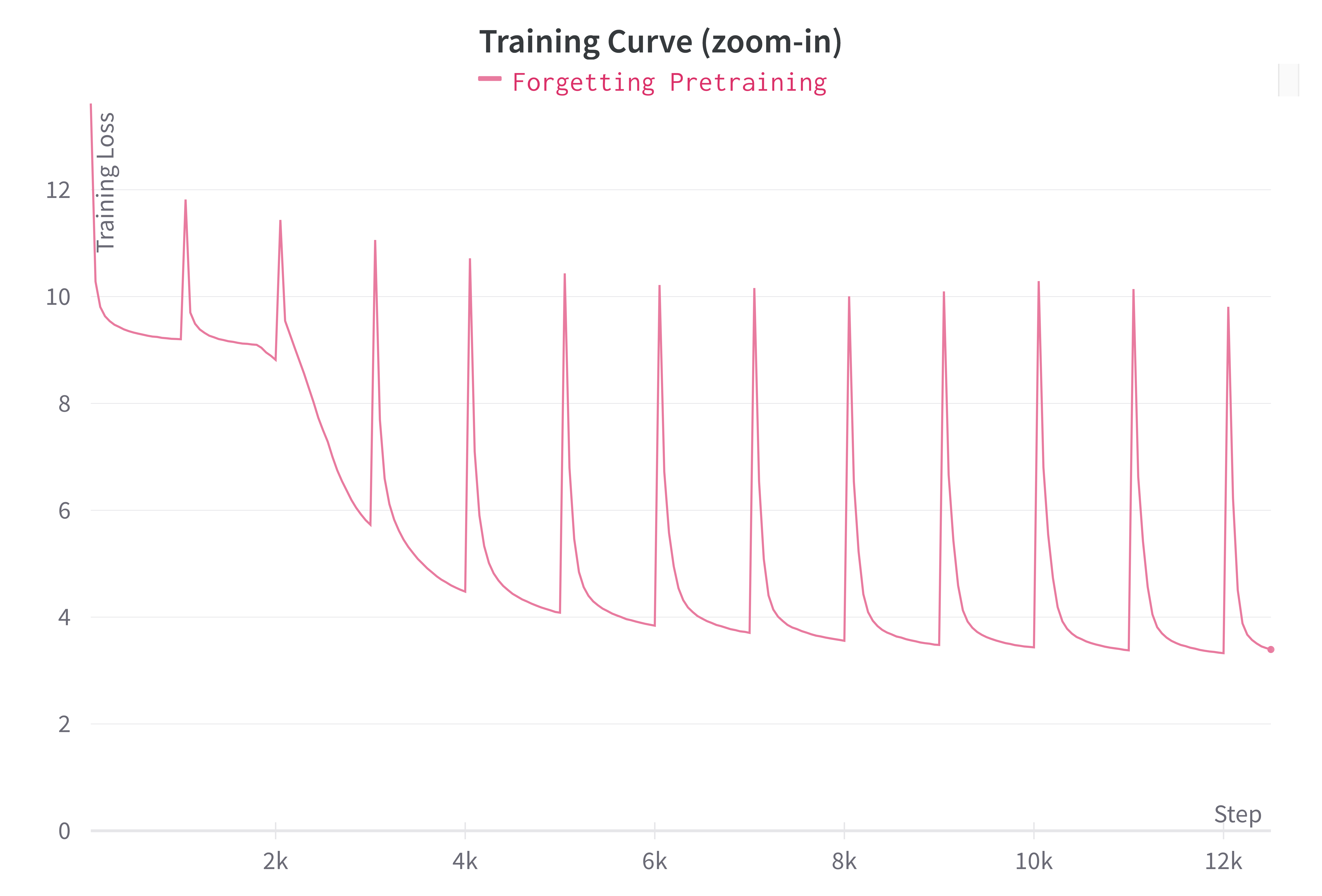
Forgetting PLMs exhibit episodic loss curves, similar to meta learning, where each reset acts as a new learning episode. This approach introduces diversity without requiring additional data, enabling better adaptation to new languages.
Authors
