The Role of Structure in Building Controllable AI
— Structure, Destructure, and Transparency
Yihong Chen
May 2025
Self-Introduction
Education:
UCL (Ph.D., CS)
Tsinghua (B.Eng., EE)
Experience:
Meta FAIR
Microsoft Research
Research:
Language Models
Knowledge Graphs
Continual Learning
Goal:
Robust, Steerable, Controllable AI
Research Theme
Structure
Explore how AI capture and acquire real world regularities
- knowledge graph
- large language model
- neural-symbolic approaches
Destructure
Explore how AI break structures for adaptability and controllability
- adapt to new inputs
- update outdated information
- remove inappropriate bias
Structure
Applied Systems
Pretraining on graphs (AKBC 2021) and texts (NeurIPS 2023)
Theoretical Contribution
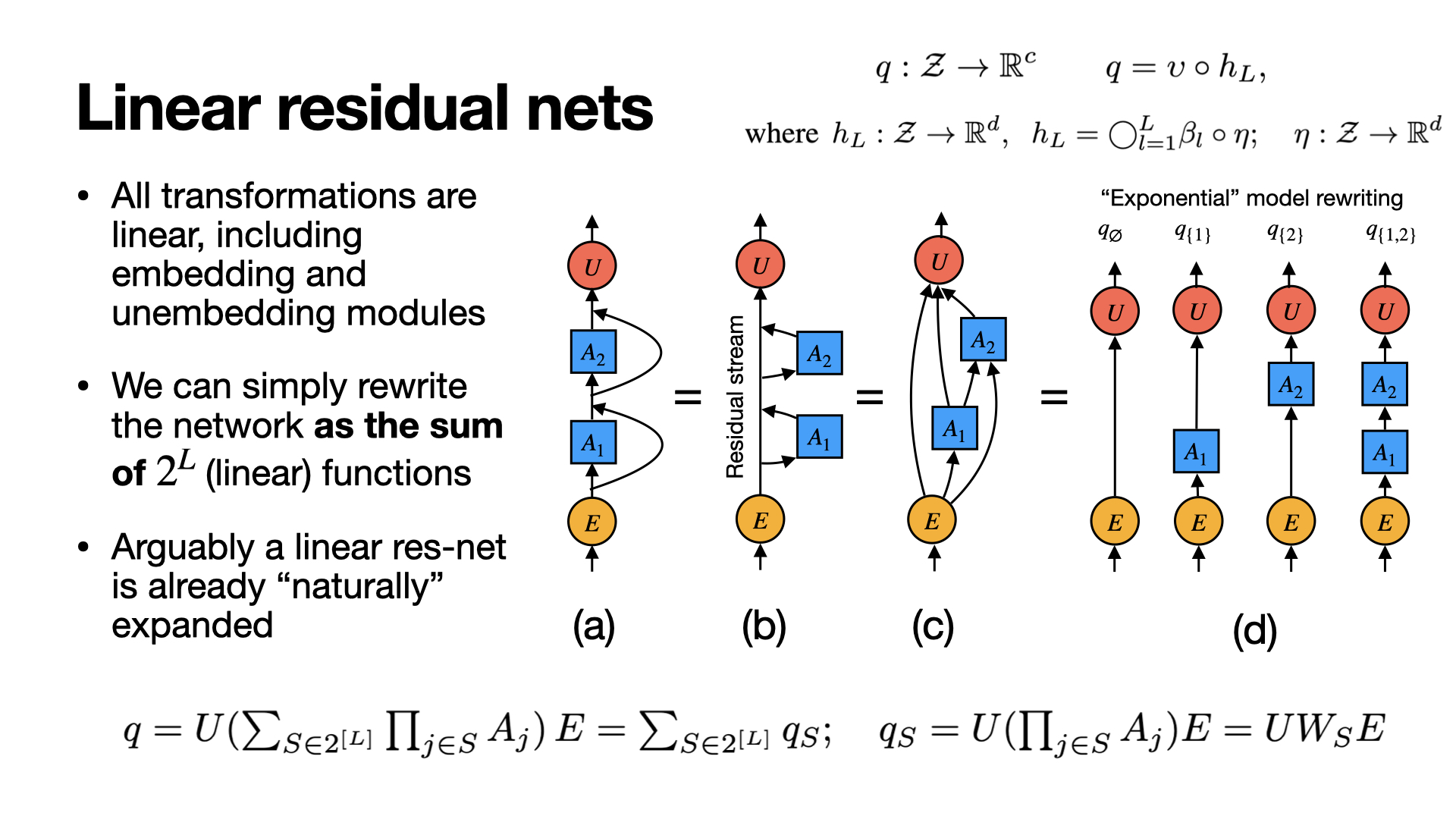
Unifying factorization models and GNNs (NeurIPS 2022)
Unify FM and GNN
\[ \begin{aligned} &\textbf{Theorem (Message Passing in FMs):} \\ &\text{The gradient descent operator } \text{GD} \text{ on the node embeddings of a DistMult model} \\ &\text{with the maximum likelihood objective and a multi-relational graph } \mathcal{T} \text{ over entities } \mathcal{E} \\ &\text{induces a message-passing operator whose composing functions are:} \end{aligned} \]
\[ q_{\mathrm{M}}(\phi[v], r, \phi[w]) = \begin{cases} \phi[w] \odot g(r) & \text{if } (r,w) \in \mathcal{N}_{+}^1[v], \\ (1 - P_\theta (v|w, r)) \phi[w] \odot g(r) & \text{if } (r, w) \in \mathcal{N}_-^1[v] \end{cases} \]
\[ q_{\mathrm{A}}(\{m[v, r, w] : (r,w) \in \mathcal{N}^1[v]\}) = \sum_{(r,w) \in \mathcal{N}^1[v]} m[v,r,w] \]
\[ q_{\mathrm{U}}(\phi[v], z[v]) = \phi[v] + \alpha z[v] - \beta n[v] \]
\[ n[v]= \frac{|\mathcal{N}_{+}^{1}[v]|}{|\mathcal{T}|} \mathbb{E}_{ P_{\mathcal{N}_+^{1}[v]} } \mathbb{E}_{ u \sim P_{\theta}(\cdot|v, r)} g(r) \odot \phi[u] + \frac{|\mathcal{T}^{-v}|}{|\mathcal{T}|} \mathbb{E}_{ P_{\mathcal{T}^{-v}} } P_\theta(v|s, r) g(r) \odot \phi[s] \]
where \( \mathcal{T}^{-v} = \{(s, r, o) \in \mathcal{T} : s \neq v \land o \neq v \} \), and \( P_{\mathcal{N}^{1}_+[v]} \), \( P_{\mathcal{T}^{-v}} \) are empirical probability distributions.
Not all knowledge are useful

Challenges of Controlling Knowledge in LLMs
Destructure & Restructure
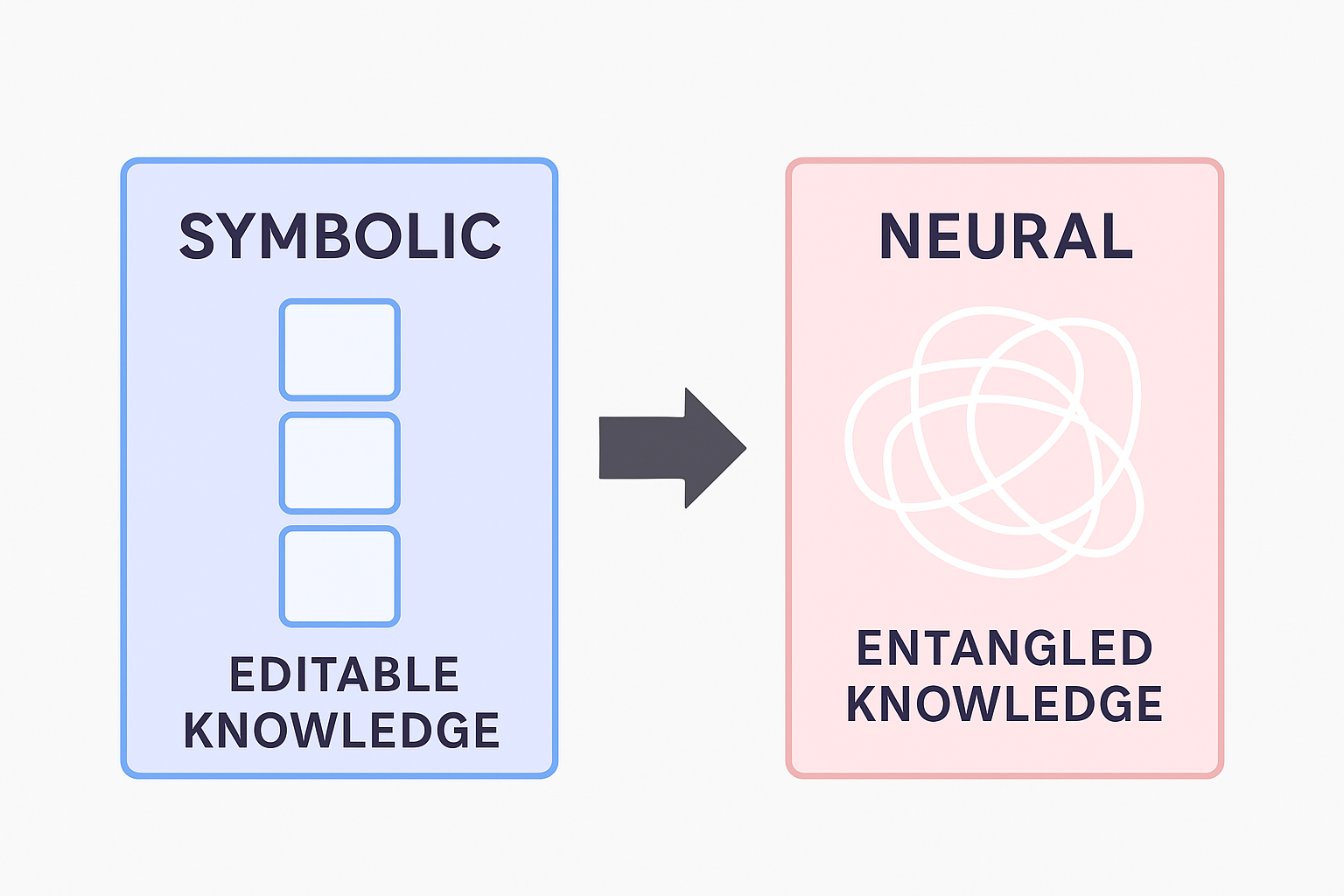
LLMs are excellent at structuring knowledge into neural weights, but poor at dismantling it. Unlike symbolic systems, they lack clearly addressable knowledge units.
Passive forgetting for removing information post-training
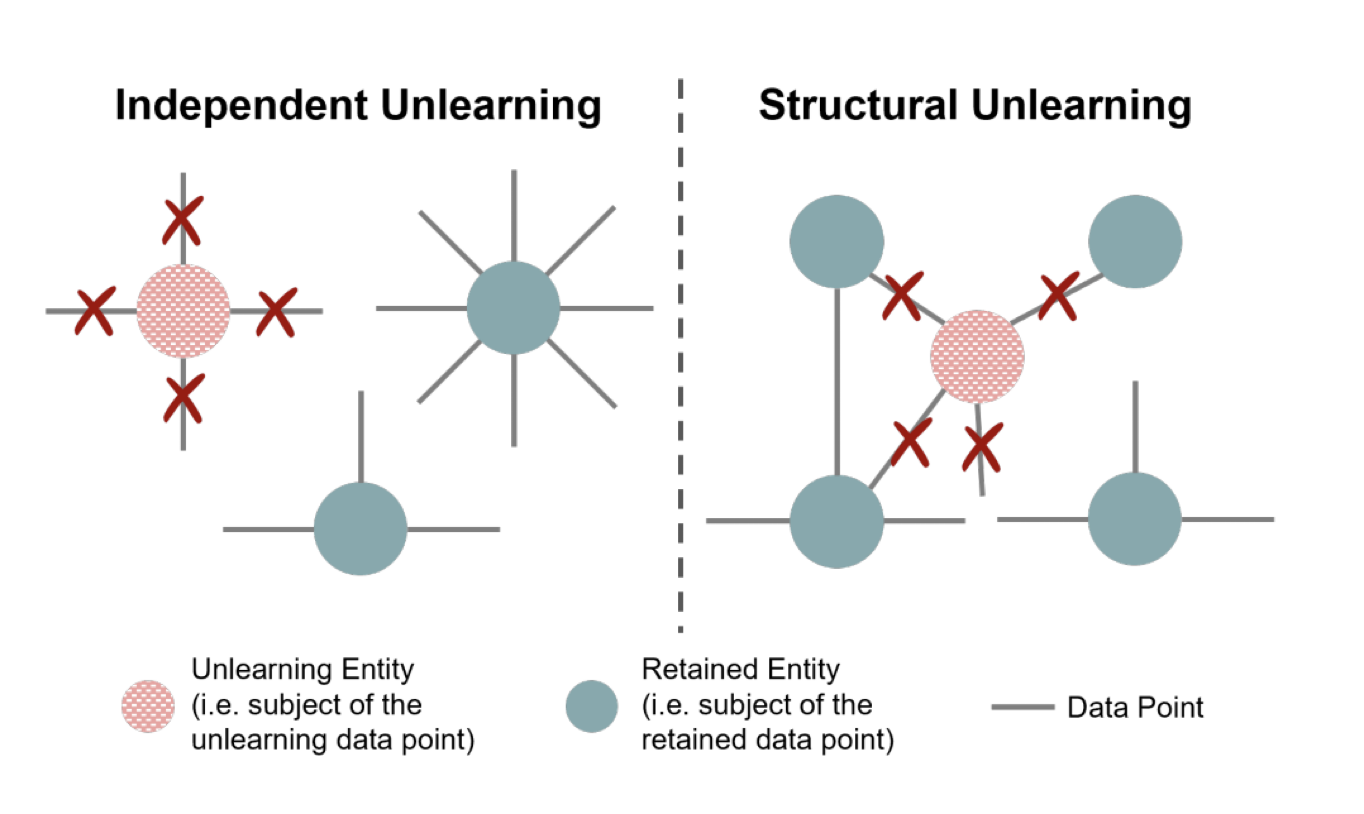
Pistol: Benchmarking Structural Unlearning for LLMs (2024); unlearning difficulty increases as data inter-connectivity grows
Active forgetting for promoting model adaptability
Active forgetting for promoting model adaptability

Active forgetting for promoting model adaptability

Active forgetting for promoting model adaptability

Active forgetting for promoting model adaptability
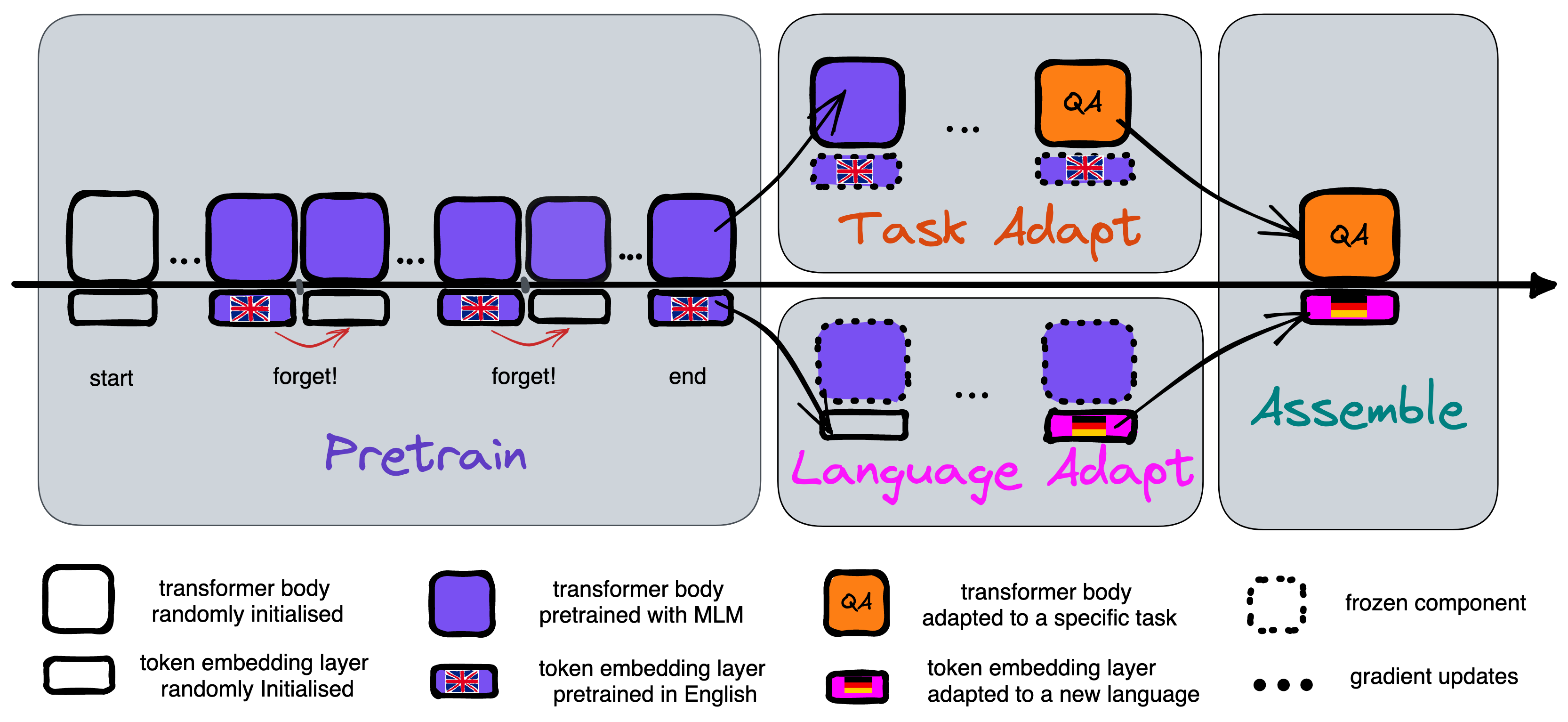
The body is not general enough so requires lots of customization to the new language
Active forgetting for promoting model adaptability
Is there any way to make the body more general?

Active forgetting for promoting model adaptability
Is there any way to make the body more general?
Active forgetting for promoting model adaptability
Is there any way to make the body more general?

Active forgetting for promoting model adaptability
Is there any way to make the body more general?

Active forgetting for promoting model adaptability
Is there any way to make the body more general?

Active forgetting for promoting model adaptability
General v.s. Specific

Active forgetting for promoting model adaptability
Meta-learning with minimal intervention during pretraining

Active forgetting for promoting model adaptability
Meta-learning with minimal intervention during pretraining

Active forgetting for promoting model adaptability
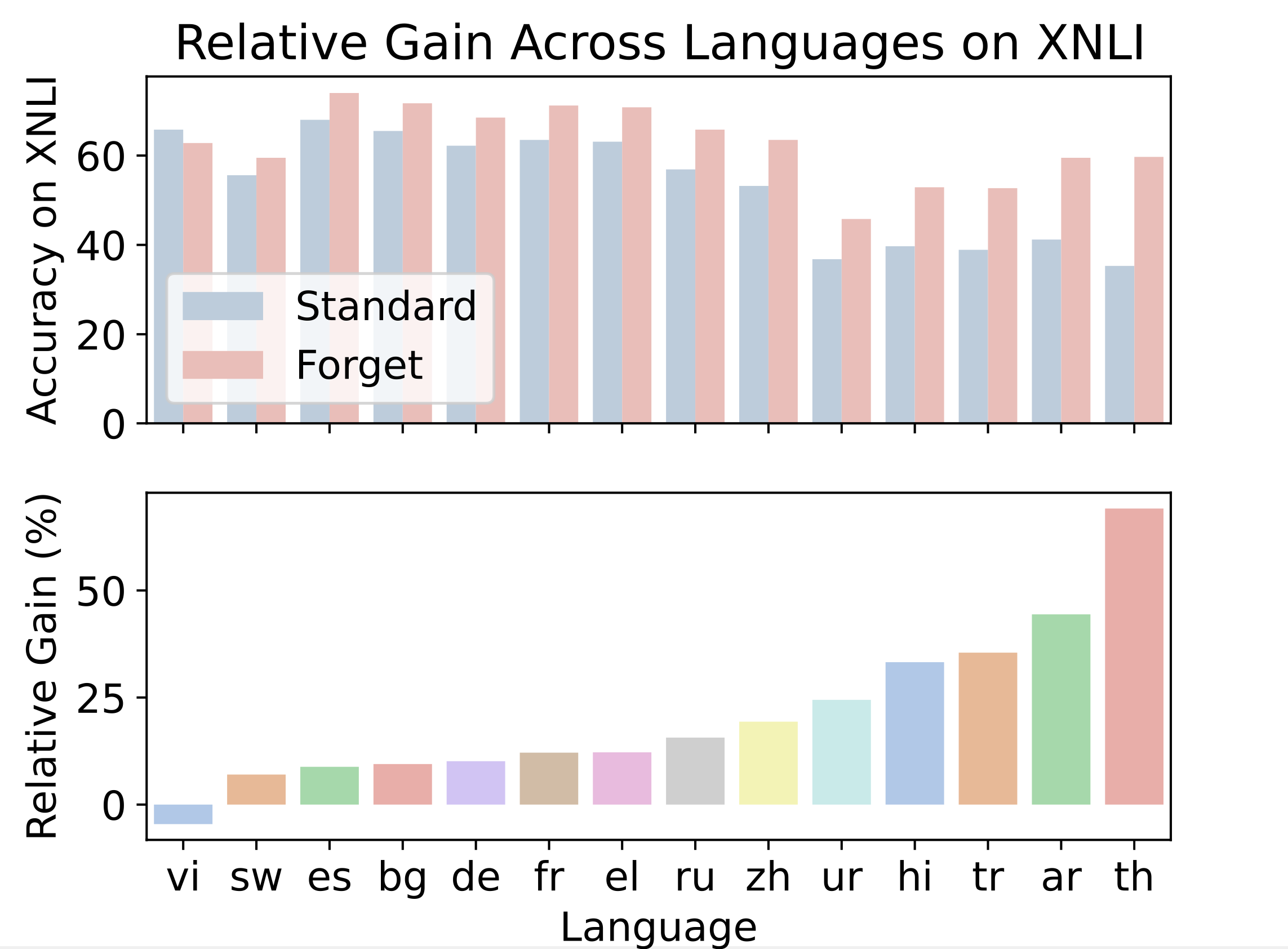
Overfitting → Collapse: Rigid models fail under distributional shift;
Solution: Active Forgetting allows training more adaptive language models (NeurIPS 2023)
Fundamentally, the model does not know what it knows — or what it does not know.
Transparentifying Knowledge in LLMs

Reformatting LLMs for making hidden model knowledge accessible.
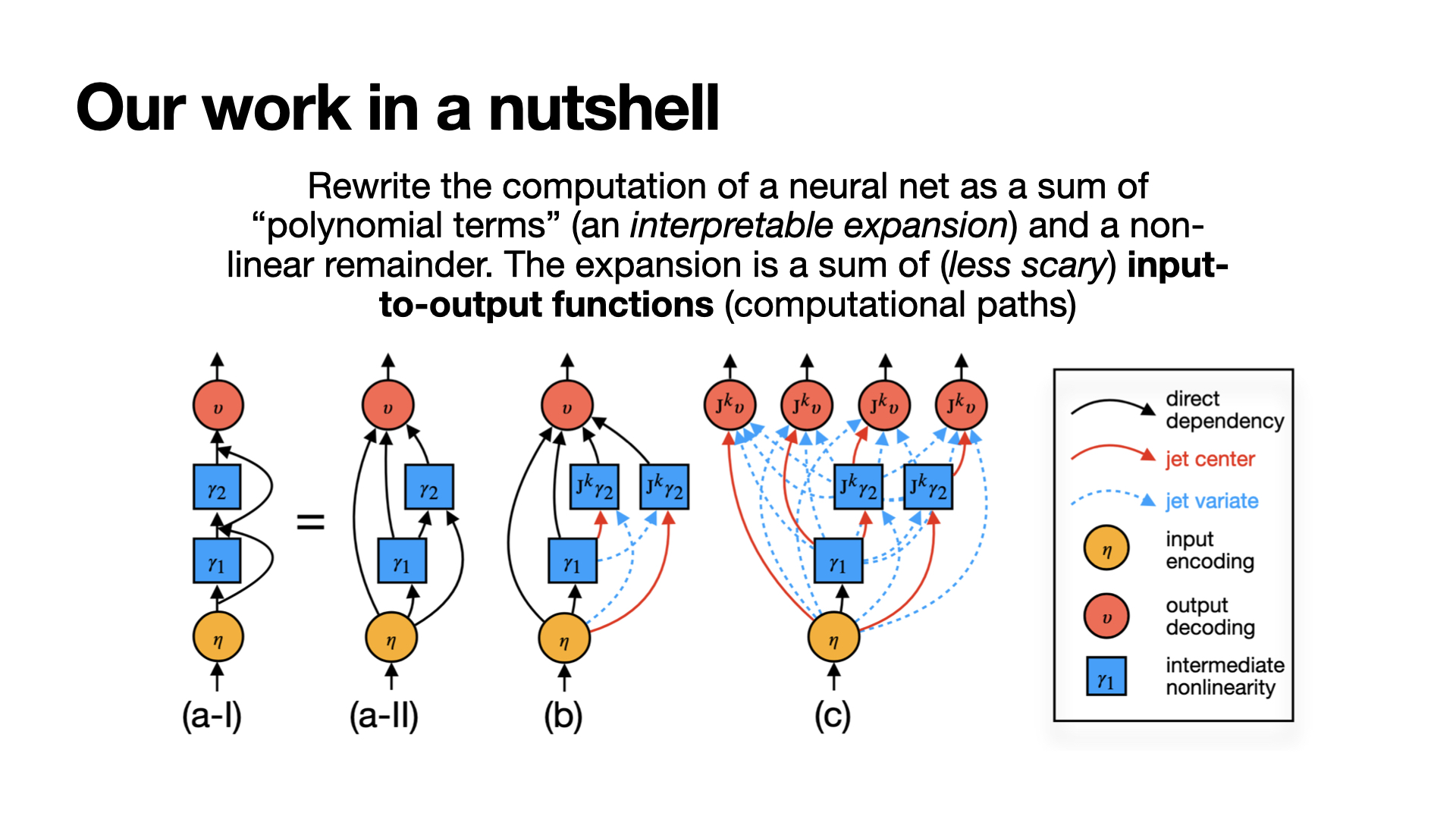
Jet Expansions (2024): Extracting human-readable symbolic structures from LLM residual computation
Preliminary Use Case 1: Tracking model maturity during pretraining steps
Early steps learn meaningless bigrams like (yaml, Adam). As training progresses, the model picks up more sensible bigrams such as (its, own) and (make, sure).
Preliminary Use Case 2: Model diff to check if finetuning effective
Preliminary Use Case 3: Quantify toxic levels
RLHF improves ToxiGen scores, but LLMs like Llama-2-7B-Chat still retain toxic knowledge. With increasingly explicit prompts, their toxicity resurfaces: 84% for hard prompts. Jet bi-gram analysis (our method) confirms that RLHF mostly hides, rather than removes, toxic patterns.
Takeaways
🧱 Structure is both a solution and a problem
It empowers learning but can also trap learning due to outdated or inappropriate knowledge.
⚖️ Controllability means both building and breaking structure
Useful structure must be constructed — but also selectively remove to support adaptation, as in Active Forgetting.
🔍 To control models, we must reveal what they know
Neural models don't store knowledge in explicit units. Tools like Jet Expansions help us surface and inspect these hidden internal structures.
Thank You!
Questions and Discussion
Yihong Chen | yihong.chen@cs.ucl.ac.uk | github.com/yihong-chen
Appendix