Structure and Destructure
Dual Forces in the Making of Knowledge Engines
Yihong Chen
University College London
Motivation
- AI needs knowledge engines to emulate human intelligence
- Structured paradigm: Knowledge Graphs
- Unstructured paradigm: Large Language Models
- Need to unify these paradigms
The Dual Forces
Knowledge engines are shaped by two underlying, complementary forces:
- Structure: Introduces patterns and inductive biases into model behavior.
- Destructure: Promotes plasticity and generalization by dismantling rigid structures.
These forces manifest across both structured and unstructured modeling paradigms.
Structured vs. Unstructured Paradigms
| Force | Paradigm | |
|---|---|---|
| Structured | Unstructured | |
| Structure | Language modeling objectives induce structure in factorization models. (Chapter 2) |
Language modeling objectives induce structure in Transformers. (Chapter 3) |
| Destructure | Active forgetting supports generalization to unseen graphs. (Chapter 4) |
Active forgetting supports generalization to unseen languages. (Chapter 5) |
Table 6.1: Structured and unstructured paradigms through the lens of structure and destructure.
Unifying the (Un)Structured Paradigm
Despite differences in implementation, a unifying lens reveals shared mechanisms:
| Force | Mechanistic Insight |
|---|---|
| Structure | Language modeling induces structured computation within models. (Part I) |
| Destructure | Active forgetting enables generalization to novel symbolic environments. (Part II) |
Table 6.2: A unified view of structure and destructure in language modeling.
Hightlight 1: Language modeling objective for knowledge graph completion (AKBC 2021)
A new self-supervised training objective
- not only predicting entities (1vsAll)
- but also predicting relations
Answer = Troy, New York
Answer = Maureen Stapleton
Answer = place_of_birth
Mathematically, we have the joint training objective as
\[ \underset{\theta \in \Theta}{\arg\max} \sum_{\langle s, p, o \rangle \in \mathcal{G}} \left[ \log P_\theta(s \mid p, o) + \log P_\theta(o \mid s, p) + {\color{red}{\lambda \log P_\theta(p \mid s, o)}} \right] \]
\[ \log P_\theta(p \mid s, o) = \phi_\theta(s, p, o) - \log \sum_{p' \in \mathcal{R}} \exp\left[\phi_\theta(s, p', o)\right] \]
Equation (2.3) Extending 1vsAll with a relation prediction term
Answer = place_of_birth
Relation as a Predictable Node
Treats all triple components as tokens:
- No privileged structure, only co-occurrence
- Like masked language modeling for triples
Results
| Dataset | Entity Prediction | Relation Prediction | MRR | Hits@1 | Hits@3 | Hits@10 |
|---|---|---|---|---|---|---|
| WN18RR | ❌ | ✅ | 0.258 | 0.212 | 0.290 | 0.339 |
| ✅ | ❌ | 0.487 | 0.441 | 0.501 | 0.580 | |
| ✅ | ✅ | 0.488 | 0.443 | 0.505 | 0.578 | |
| FB15K-237 | ❌ | ✅ | 0.263 | 0.187 | 0.287 | 0.411 |
| ✅ | ❌ | 0.366 | 0.271 | 0.401 | 0.557 | |
| ✅ | ✅ | 0.388 | 0.298 | 0.425 | 0.568 | |
| Aristo-v4 | ❌ | ✅ | 0.169 | 0.120 | 0.177 | 0.267 |
| ✅ | ❌ | 0.301 | 0.232 | 0.324 | 0.438 | |
| ✅ | ✅ | 0.311 | 0.240 | 0.336 | 0.447 |
Table 2.3 The new objective brings consistent improvements across all datasets on all metrics except Hits@10 on WN18RR.
Highlight 2: Active Forgetting for Model Adaptability (NeurIPS 2023)
Transformer-based language models

Rewire language models for new languages

Freeze body, relearn embeddings (Artetxe et al 2020)

Hidden assumption on the transformer body
The body in practice is not general enough and requires lots of data to adapt to the new language
Train models that are naturally good at adaptation
Is there any way to make the body more general?
A model with general body will be plastic to new embedding learning.
Active forgetting -- Train
Is there any way to make the body more general?

Active forgetting -- Forget
Is there any way to make the body more general?

Active forgetting -- Repeat
Is there any way to make the body more general?

Active forgetting -- Repeat
Is there any way to make the body more general?

Active forgetting
General v.s. Specific

A meta-learning view on active forgetting
Meta-learning with minimal intervention during pretraining

A meta-learning view on active forgetting
Meta-learning with minimal intervention during pretraining

Results
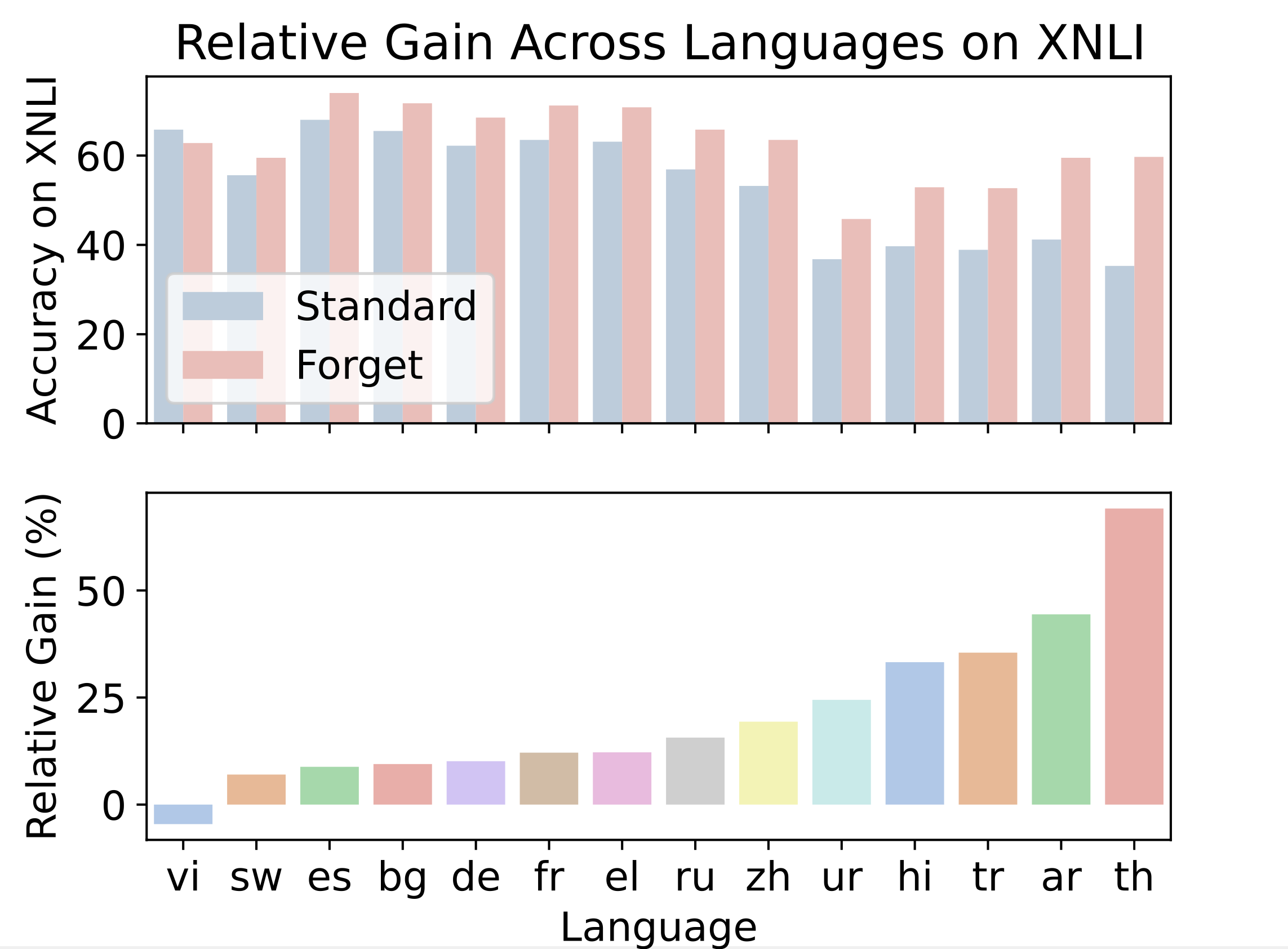
Figure 5.6: Relative gains of forgetting PLMs over standard PLMs across languages for XNLI. Forgetting yields substantial relative gains for languages like Arabic, Hindi, Thai, Turkish, and Urdu.
Limitations
- Theoretical Breadth: The thesis focuses on relational and language-induced structures, but does not deeply engage with broader structural notions from cognitive science, mathematics, or symbolic AI.
- Destructuring Scope: Active forgetting targets embeddings, while ignoring other model components; automatic scheduling and selection remain unexplored.
- Evaluation Diversity: Generalization is tested only on unseen entities/languages; other realistic shifts (e.g., domain, temporal, personalization) are not evaluated.
- Scalability & Transparency: Structure extraction (e.g., n-grams, attention paths) lacks scalability; broader model coverage and validation are required.
Thank You!
Questions and Discussion