On the Role of Structure
in Building Controllable AI
— Where Is the Control Knob?
Yihong Chen
ILCC Seminar, 27 Feb 2026
About Me
Postdoc
OATML, Oxford
Research
knowledge representation, abstraction, and acquisition
(KGs & LLMs)
PhD (CS)
FAIR & UCL
Goal
build computational systems that reproduce and improve human knowledge acquisition.
Why? Controllability needs knowledge manipulation operators.
Is there a control knob for the LLMs?
Data-Centric Control
Most current interventions operate through the data distribution.
- Supervised finetuning
- RLHF / DPO
- Filtering pretraining corpora
- Continual data updates
Indirect, expensive, and prone to model collapse under repeated synthetic training.
What about model-level control?
Why Model-Level Control Is Hard in LLMs
| Knowledge Graph | LLM | |
|---|---|---|
| Deletion | Remove edge | Indirect parameter updates |
| Update | Add fact | Indirect parameter updates |
| Transparency | High | Low |
| Knowledge unit | Node / triple | Entangled representation |
In symbolic systems, knowledge maps to explicit units. In LLMs, knowledge is distributed, so control is usually indirect -- no turnable knobs.
Problem Essence: Knowledge Layout != Computation Layout
model internals
facts and behavior
Turning the knob in computational space should produce targeted change in knowledge space (e.g. deletion of a fact) while preserving unrelated capabilities (e.g. the other facts intact).
This leads to two complementary directions: first, carve the knob by decomposing model computation; second, make the knob turnable by improving model plasticity.
Model decomposition carves the knob.
Can we decompose LLMs?
Yes, functionally.
LLMs as Recursive Residual Networks
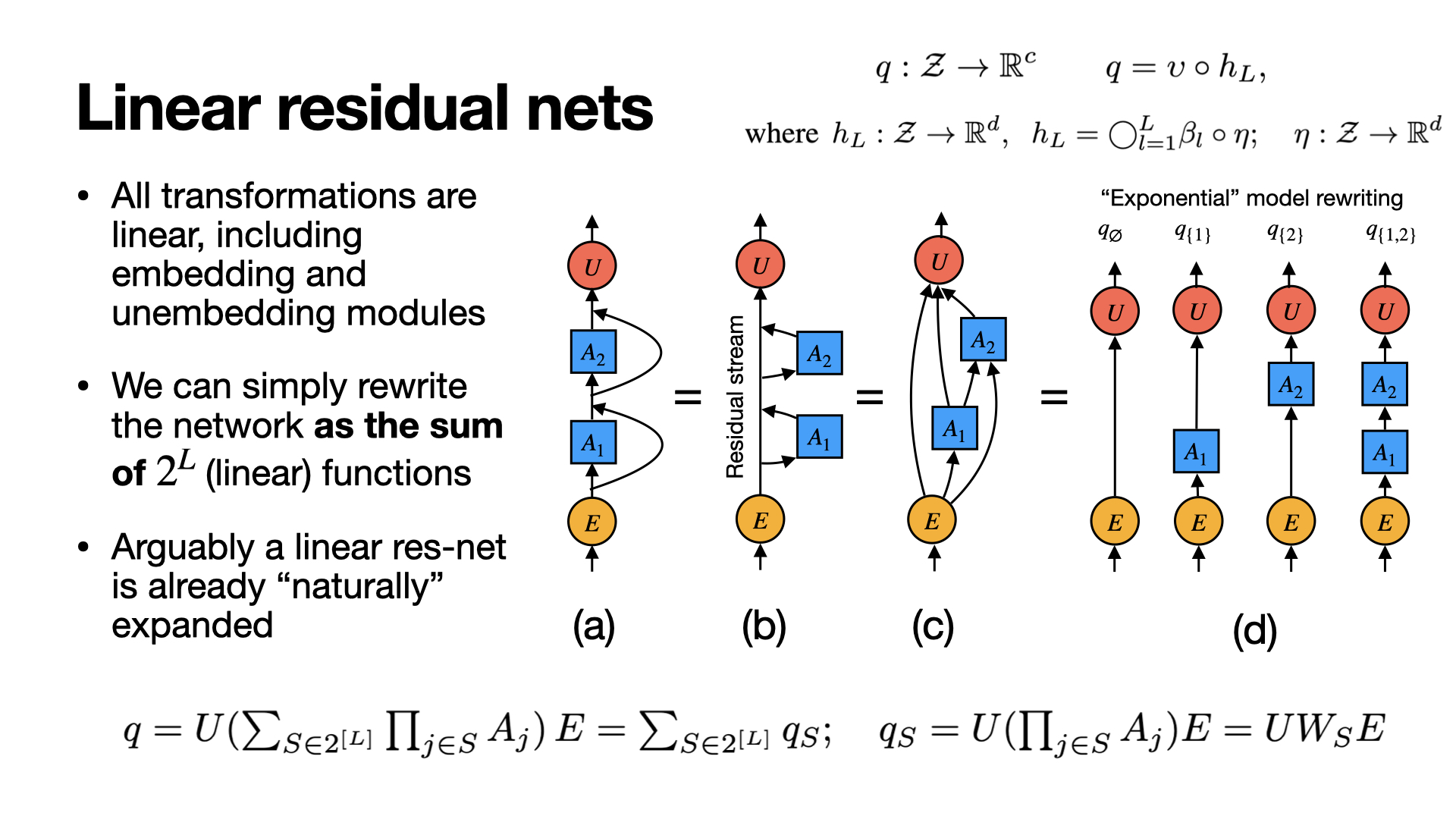
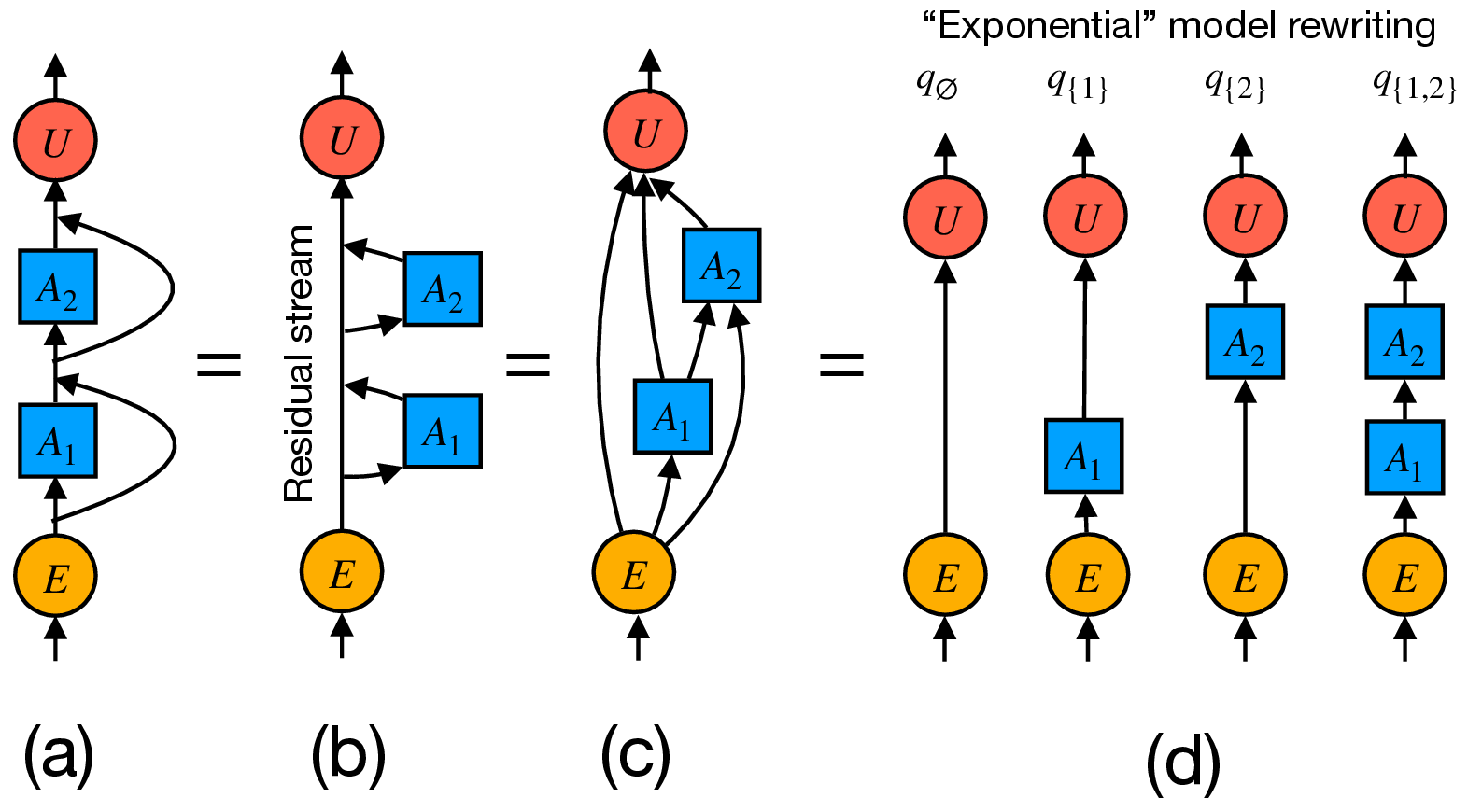
A model is just a function no matter which architecture. We can write the model as nested residual maps:
\( f = \mathrm{Dec} \circ \Big(\circ_{\ell=1}^L (\mathrm{id} + \gamma_\ell)\Big) \circ \mathrm{Enc} \)
Hidden recursion:
\( h_\ell = h_0 + \sum_{j=1}^\ell \gamma_j(h_{j-1}) \)
Residual links accumulate nested nonlinear contributions (source of entanglement).
Linear Residuals: Exact Path Decomposition
Non-linear Case: Local Polynomial Expansion
For \(f\in C^{k+1}\) around basepoint \(x_0\):
\( f(x) = f(x_0) + \sum_{j=1}^k \frac{1}{j!} D^j f(x_0)\,(x-x_0)^{\otimes j} + O(\|x-x_0\|^{k+1}) \)
Jets: define the k-jet operator \( J_k f(x_0) \) as the truncated polynomial component.
Interpretation: each derivative tensor isolates interactions of specific orders.
Non-linear Case: Local Disentanglement of Jets (Sketch)
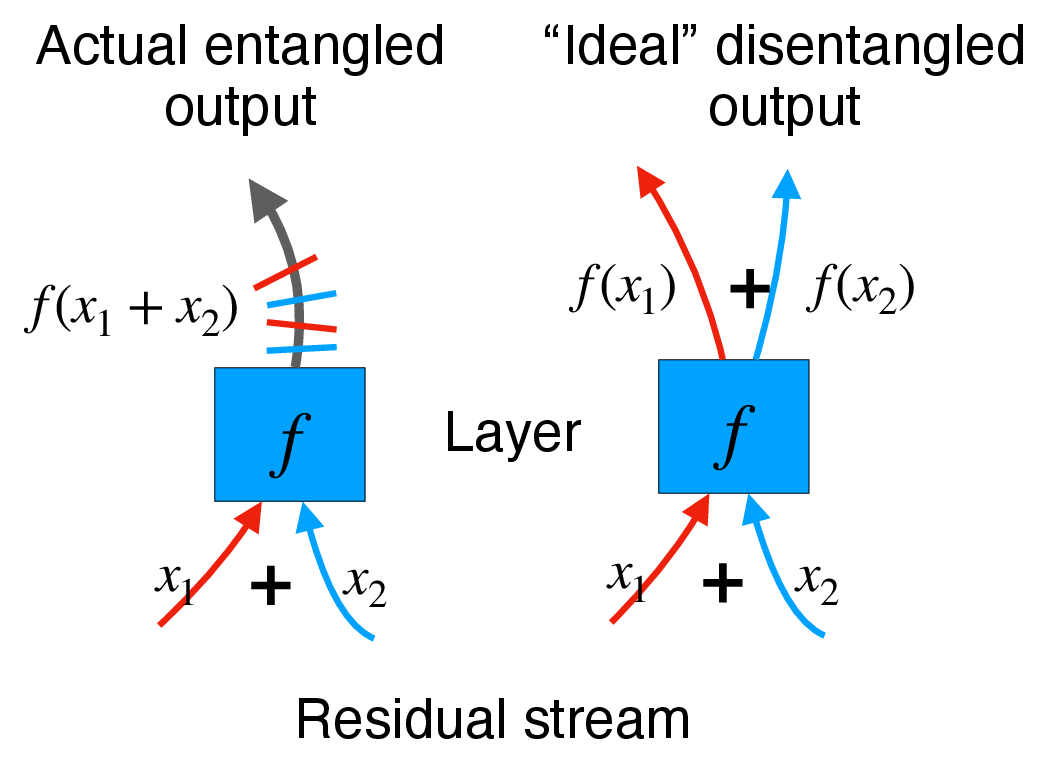
Setup. Let \( \bar{x} = \sum_{i=1}^N x_i \).
Claim. For sufficiently small interaction radius \(r\),
\( J_k f(\bar{x}) = \sum_{i=1}^N w_i\, J_k f(x_i) + O(r^{k+1}) \)
Why this matters. Jets are approximately a convex combination of component jets, with controlled error. This gives a principled way to separate nested residual streams passing through one nonlinear block.
Non-linear Case: Recursive Jet Disentanglement
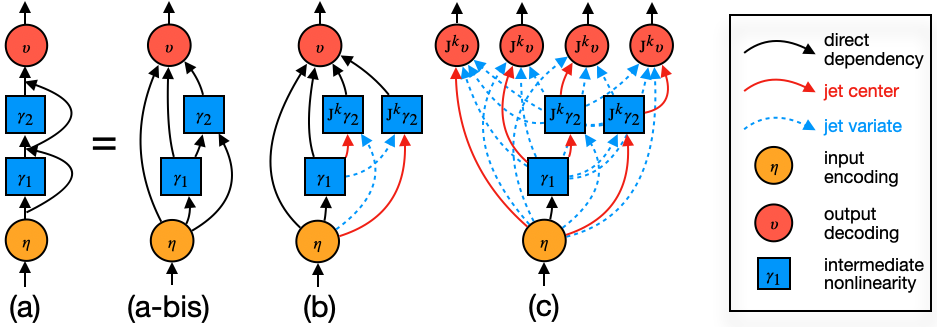
Implications of the jet decomposition
1) Redundancy. Transformers behave like ensembles over exponentially many skip/non-skip paths across scales, giving multiple pathways to carve.
2) Unification. Many interpretability methods are low-order decompositions: keep the terms we care about, discard the remainder.
Jet-order intuition (local expansion):
- 0th order: direct output readout (logit lens)
- 1st order: local linear response (gradient attribution)
- Higher orders: interaction terms (less useful empirically)
Are the Carved Pathways Meaningful?
Extract in-model bigrams from low-complexity pathways by sweeping the vocabulary.
Then test whether these bigrams track learning during pretraining and change appropriately after finetuning.
Evidence 1: Carved-pathway bigrams track pretraining maturity
Early checkpoints show noisy pairs (for example, yaml Adam), while later checkpoints surface more coherent pairs (for example, its own, make sure).
Evidence 2: Carved-pathway bigrams verify finetuning effects
Model-level bigram shifts provide a direct check of whether finetuning changed the targeted knowledge.
Evidence 3: Quantify toxic levels
RLHF improves ToxiGen scores, but LLMs like Llama-2-7B-Chat still retain toxic knowledge. With increasingly explicit prompts, their toxicity resurfaces: 84% for hard prompts. Jet bi-gram analysis (our method) confirms that RLHF mostly hides, rather than removes, toxic patterns.
Alignment: Is Deeper Alignment Deep Removal or Masking?
Blue: toxic mass change. Orange: refusal mass change.
Setup
Compare Llama2-7B-Chat vs augmented model
(Qi et al., ICLR 2025).
Relative bigram mass:
\( \frac{M_{aug} - M_{chat}}{M_{chat}} \).
Toxic Bigram Mass
Joint metric ≈ −0.05% (no global removal).
Most layers: −0.5% to −2%.
Refusal Mass
Increased in mid–late MLP layers. Final layer (MLP32): +8.43%.
Interpretation
Alignment reshapes depth-wise distributions and reinforces refusal
signatures rather than erasing toxic representations.
Xiangyu Qi et al. Safety Alignment Should Be Made More Than Just a Few Tokens Deep. ICLR 2025.
Can we make this knob turnable?
Yes, with model plasticity.
Model Plasticity: Makes a Knob Turnable
Definition. A change in computation should cause a targeted change in knowledge (e.g., removing one fact) while preserving unrelated capabilities.
Design principle. Modularize the system into:
- Part I Swappable: where we can update
- Part II Invariant: provides stable capability under updates
Active Forgetting for Model Plasticity
A straightforward split: Part I token embeddings, Part II transformer body.

Active Forgetting for Model Plasticity
Question: can we make the body more general?

Active Forgetting for Model Plasticity
Apply controlled perturbations to embeddings during pretraining.

Active Forgetting for Model Plasticity
The body repeatedly recovers, learning invariance to lexical shifts.

Active Forgetting for Model Plasticity
Result: stronger generalization with targeted intervention.

Active Forgetting for Model Plasticity
General vs. specific representations.

Active Forgetting for Model Plasticity
Meta-learning with minimal intervention during pretraining.

Active Forgetting for Model Plasticity
Repeated reset-and-recover cycles induce plasticity.

Experimental pipeline
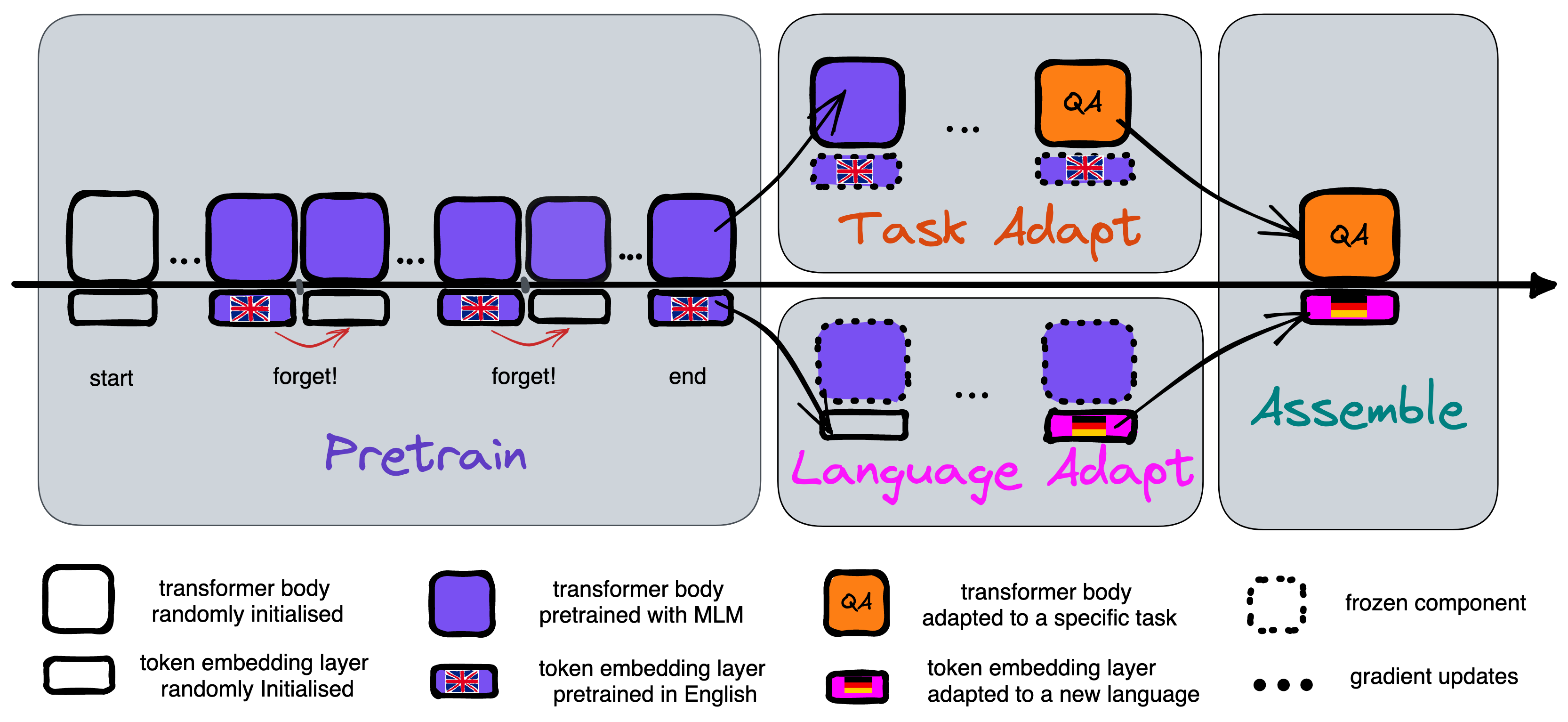
Active forgetting for promoting model plasticity
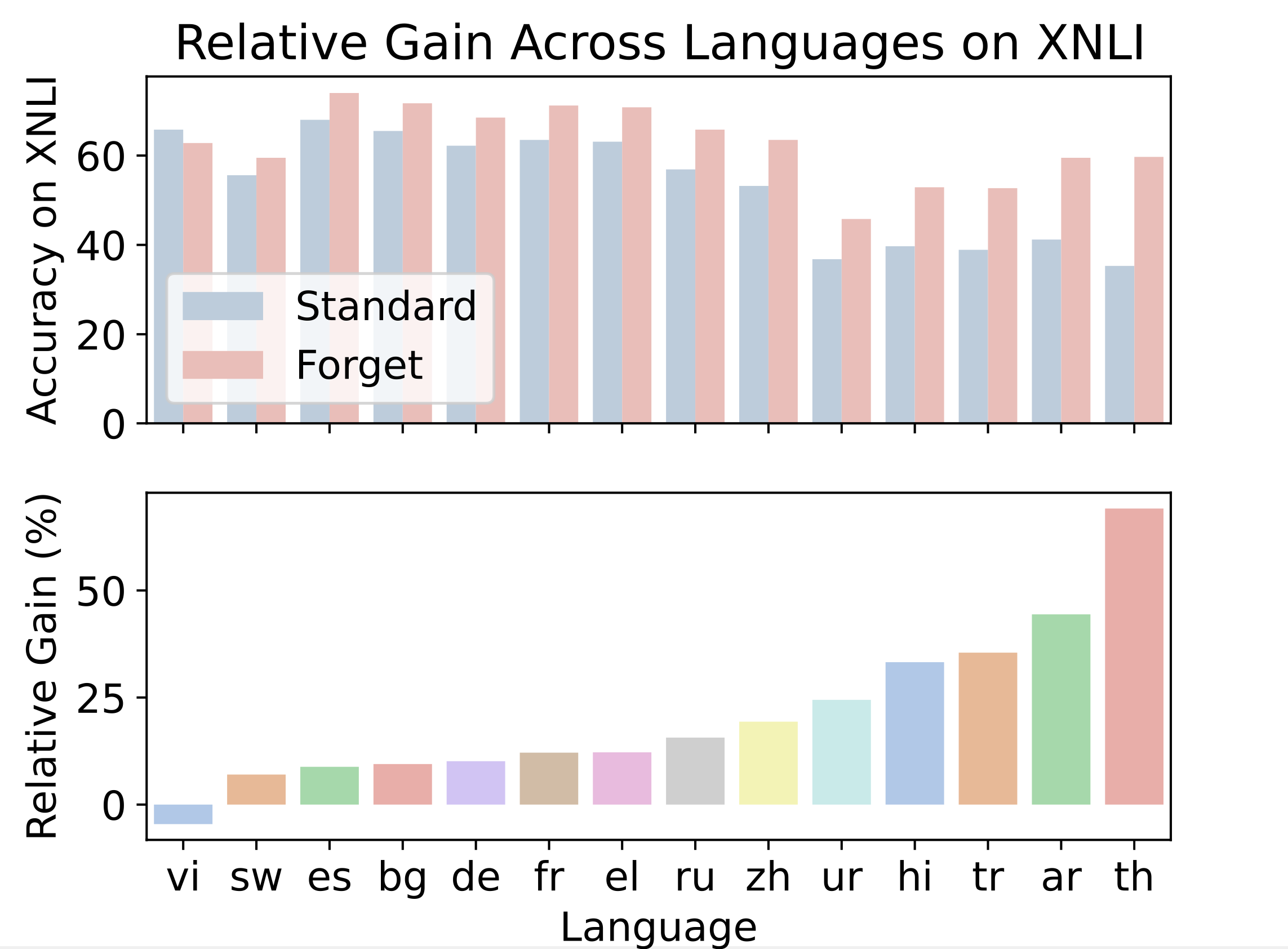
Active Forgetting: Cross-Lingual Averages
| Benchmark | Standard PLM | Forgetting PLM | Relative gain |
|---|---|---|---|
| XNLI (Acc) | 53.3 | 62.7 | +21.2% |
| MLQA (F1) | 34.3 | 43.4 | +33.8% |
| XQuAD (F1) | 36.1 | 49.0 | +60.9% |
| XQuAD @5K updates | 53% of final | 92% of final | faster adaptation |
Takeaways
1) Why control is hard
LLM knowledge is distributed and entangled, so data-level fixes can miss model-level structure.
2) Decomposition gives visibility
Jet decomposition reframes transformers as structured sums of computation paths, enabling interpretable probes such as in-model n-grams.
3) Plasticity makes intervention possible
Active Forgetting trains models to tolerate controlled perturbations, enabling targeted updates while preserving unrelated capabilities.
Bottom line
Controllability requires both: decomposition to diagnose and plasticity to intervene.
Limitations and Open Questions
- Model decomposition: Are 0th- and 1st-order terms sufficient to explain behavior, or do they capture only part of model memory?
- Model decomposition: How close are LLMs to an \(L\)-nested matrix factorization of web-scale text?
- Model plasticity: Which intervention tools work best, and how do effects vary across time and domains?
- Decomposition + plasticity: Can the two be combined to make selected paths (circuits) reliable control knobs?
Thank you
Questions? yihong.chen@cs.ox.ac.uk
Appendix: Jet nutshell
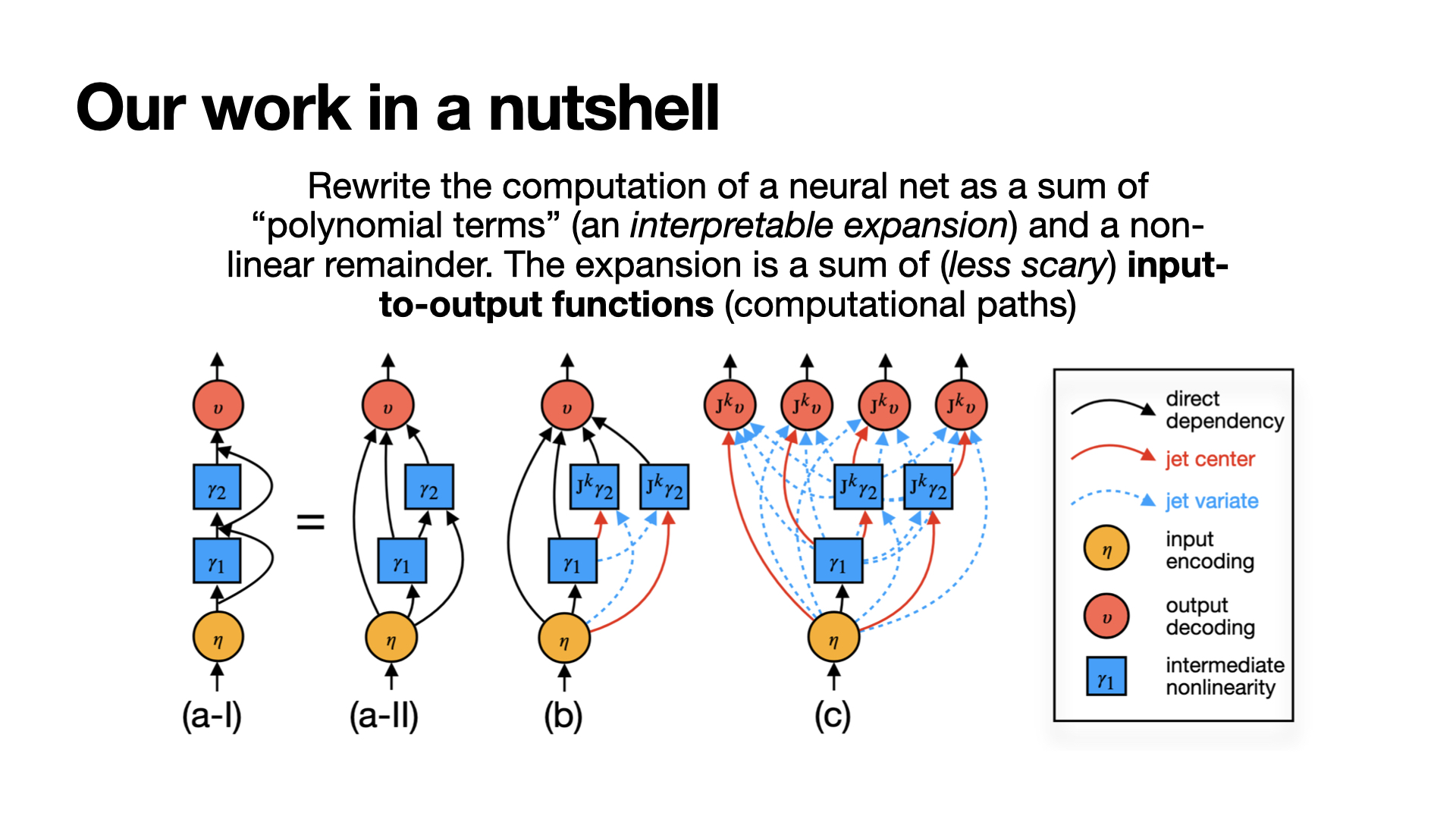
Appendix: Jet linear example